

PowerBI DAX中有哪些性能优化方法?
在用PowerBI DAX查询总是运行很慢,针对PowerBI DAX性能优化,有什么好的方法可以介绍下?
我是BI佐罗,目前在全球最大跨国奢侈品零售集团担任商业智能架构师,针对性能优化,在 DAX 中是很重要的问题,对 DAX 的性能优化大致可以归结为针对 SE(存储引擎) 或 FE(公式引擎) 的性能优化。(文末有福利赠送)
如果可以确保 SE 和 FE 都在最好的状态下工作,那么 DAX 将得到充分的发挥。而往往分析师会更加关注业务逻辑的表达,但我们开始研究写出更快的 DAX 时,我们将成为会修车的分析师了。我们会通过一系列文章来帮助大家在各个角度来体会 DAX 的性能优化技术。
今天我们来看一个案例。
看一个案例,我们想知道大订单的个数,如下:
OrderPurchaseNumber=CALCULATE(
DISTINCTCOUNT( 'Order'[OrderID]) ,
FILTER(
'Order' ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
)
大订单的定义为包含单价大于1000且利润大于0的订单。
这个定义没有问题,放在 PowerBI 中的计算也是正确的,但不久就会发现它的性能问题,于是,通过 DAX Studio 来检查可以看到:

我晕,居然惊现了 779 个查询。
该查询的意义是计算每天的大订单个数。但这种方法显然是不行的。虽然在度量值的定义上非常自然。
我们再来看看从 PowerBI 中拖拽的情况,如下:
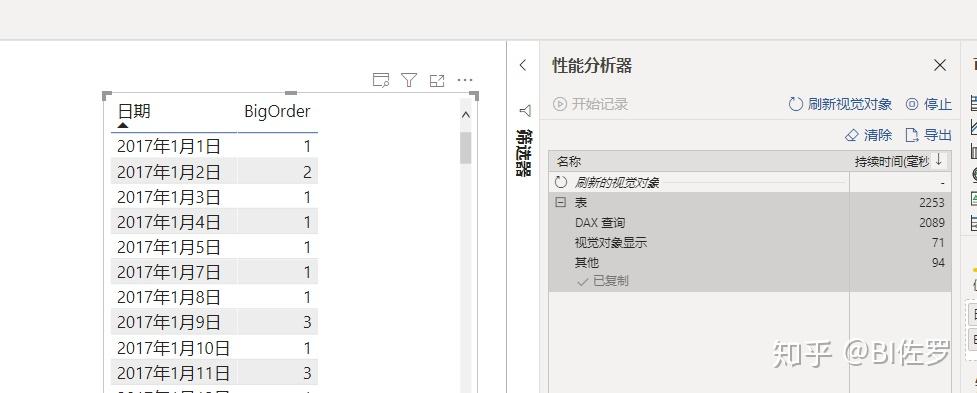
如果研究该图表背后的 DAX 查询,其结果和上述内容是一致的。
那么问题来了,我们建立了一个基础度量值叫:OrderPurchaseNumber,其逻辑也很清楚,但却有如此之差的性能,怎么办呢?
这里的问题在于发起了对 SE 的多次查询,不难察觉:
FILTER(
'Order' ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
这里使用了 Order 表作为 FILTER 的参数,而且位于基础度量值的位置,导致在迭代日期时,每次都会做单独计算,导致对 SE 的过度重复访问。
有一种做法是,可以将度量值改为:
OrderPurchaseNumber=CALCULATE(
DISTINCTCOUNT( 'Order'[OrderID]) ,
FILTER(
ALL( 'Order' ) ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
)
注意,这里用了 ALL( 'Order' ) 而非 'Order' ,这显然是不对的,因为它改变了语义。
那么进而想到另一种方式为:
OrderPurchaseNumber=CALCULATE(
DISTINCTCOUNT( 'Order'[OrderID]) ,
FILTER(
ALL( 'Order'[LinePrice], 'Order'[LineProfit]) ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
)
这样的方式仅仅使用需要用到的两列,而非整个表,来看下效果:

性能得到了非常恐怖的提升。
但细心的伙伴会发现,这种写法的努力方向是对的,但这种写法还是错误的,因为:
FILTER(
ALL( 'Order'[LinePrice], 'Order'[LineProfit]) ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
作为筛选器参数,会覆盖外部的筛选,这也是不正确的逻辑,所以,需要进一步优化为:
OrderPurchaseNumber=CALCULATE( DISTINCTCOUNT( 'Order'[OrderID]) ,
KEEPFILTERS(
FILTER(
ALL( 'Order'[linePrice], 'Order'[LineProfit]) ,
'Order'[LinePrice]> 1000 && 'Order'[LineProfit]> 0
)
)
)
性能结果为:
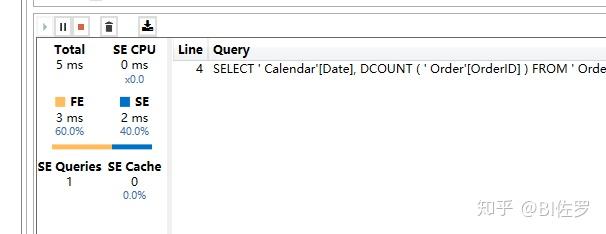
完美。
当需要在基础度量值中使用筛选条件时,必须注意:
- 仅仅使用所必须的列,提升性能
- 使用 KEEPFILTERS 包裹,确保逻辑正确
这样,基础度量值就可以携带复杂的筛选器参数而不影响性能了。
结尾了给大家赠送个福利,我专门整理了Power BI 学习资料(里面有很多学习课程是我亲自开发的,其中还有一些是付费的教程),主要包含有 Power BI 介绍、新手入门、以及直播视频等。
?想要 PowerBI 学习资料的同学,点击下面的链接即可获取。
点此领取 PowerBI 学习资料我的最后,如果你想了解更多 Power BI 相关知识,我的知乎号主页也会经常分享很多关于PowerBI 领域的全球大事,以及我平时直播预告信息,可以点击我号主页查看。
我是BI佐罗,让 Power BI 成为你职场发展的核心竞争力PS:关于 "PowerBI DAX中有哪些性能优化方法?"这个问题,我后期还会不断更新。 如果这个回答对你有所帮助,那就顺手点个赞同, 感谢你的支持!

本文共计8570字,阅读本文预计需要22分钟。
文章来源:简书
作者:我的大鹏老师,本文作者授权转载

掌握正确的Power BI优化技巧,可以帮助我们提高使用效率及使用感受,下面就总结下我整理出来的Power BI优化最佳实践。文中出现的测试数据,均使用本地电脑环境进行测试,仅做对比测试,相关数据,来至多次测试结果的平均值。
文章原来的初衷是写Power BI性能优化部分,不过随着文章的不断深入,知识边界顺带就拓宽了很多,于此题目就变成了Power BI优化最佳实践。
内容导航<上下滑动查看>
一、从数据库加载数据更快
二、只导入需要的表列
三、使用合适的数据格式2
四、不在Power Query做复杂的数据清洗
五、使用SQL加载到Power Query
六、使用参数化
七、不做大宽表
八、使用合适的数据粒度
九、减少使用新建列
十、使用表和文件夹管理度量值
十一、命名规范
十二、模型分层
十三、永远使用一对多关系
十四、反结构化设计
十五、关闭数据加载的所有选项
十六、优化DAX公式
十七、减少页面可视化对象数量
十八、使用增量刷新
十九、减少列不重复值
二十、硬件优化
二十一、定期更新Power BI Desktop
由于文中涉及大量的专业知识,受限于作者的水平,可能存在有误的地方。若发现错误之处,还望不惜赐教。测试数据样本及测试环境如下。
行数:100万列数:44列Excel文件大小:275633KB(约276M)数据库:MySQL(8.0.28.0)CPU:AMD 5600U内存频率:3200Power BI版本:2021年12月
从数据库加载数据,比从本地Excel文件加载数据,速度更快。同样的数据量,多个文件比单个文件快。
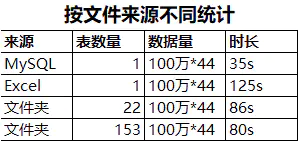
总结:可以很明显的看出,从数据库加载同样大小的数据,速度最快,而且非常明显。其中从文件夹下面加载多个Excel文件的速度,超出意外的更快,而且貌似文件越多,速度还有提升的趋势。最没想到的是单个Excel文件加载居然是最慢的。其他人也可以测测是不是真的这样。
加载多余的列,会造成两个不好的影响:
- 加载速度变慢 建议是仅仅加载在后续分析中使用的列。
- 若有新的变动,可以再有针对性的增删列。
- 造成文件变大 Power BI发布有1G的限制,因此文件大小会影响报告发布。
- 在不影响模型使用的前提下,可以尽量降低文件大小。
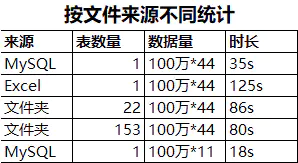
以上图的对比来看,从MySQL加载44列需要35s,加载11列只需要18s,速度快了一倍。所以,减少加载的列,可以明显减少数据加载所需的时间。
总结:只加载需要的表列,就是该条优化的最佳实践。
使用订单金额作为测试列
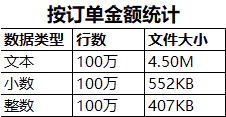
当一个数值足够大的时候,储存为文本和存储为整数的文件大小差异会变小。
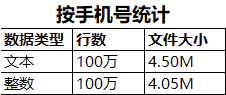
总结:可以看出,同样的100万行数值,以整数类型存储,占用的存储空间最小。在实际操作中,可以将客户编号、类型编号等存储为整数类型。
Power Query功能强大有目共睹。但在处理一些复杂计算的时候,对硬件配置要求比较高,尤其是对CPU的要求很高。因此不建议在Power Query中做太过复杂或会造成计算变慢的操作。比如使用分组依据、合并查询等,就会明显造成数据加载速度变慢,数量越大,差异就越明显。
当然,对于真正的高手来说,熟练掌握各种缓存机制及高端操作,依然可以把Power Query的运算做的很快,不过这些并不适合新手。在你无法轻松驾驭Power Query之前,依然建议遵循减少使用的原则。
举个例子:
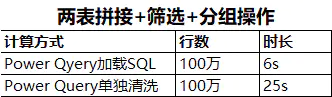
Power Query单独清洗,时间长的原因是,Power Query需要将整表加载进来,然后再使用合并查询、筛选、分组统计,因此时间比直接使用SQL查询要长很多。而且随着后续操作的步骤越来越复杂,速度也会越来越慢。
总结:如果你的数据源质量很差,且没有太多其他选择,同时数据量又不太大的情况下,也是可以选择使用Power Query做一些数据清洗的,毕竟工具的定位就是数据清洗。活学活用,找到自己的平衡点。
这种方式有很多优点。
使用Power Query加载一段SQL获取数据,相当于加载的是数据库视图查询。当库表结构变动时,对于这段连接关系影响最小,也就是减少了耦合。在模型后期的维护中,工作量最小。
并且可以灵活的调整这段查询语句。在某些场合,我们不仅仅只使用一张表,那么就可以使用SQL做拼接之后,直接加载这段查询语句,而不需要IT再做其他的支持。
而相对的,不建议做的事情就是。加载了整张表,或者加载了很多表,在Power Query中使用合并查询或分组依据功能进行计算,则计算效率会下降非常明显。
还有一个细节,有些数据来源不支持编写SQL查询。比如从Impala获取数据,只能直接添加表到Power Query。这种情况下,推荐使用ODBC作为中继,将源数据配置成ODBC连接,然后使用Power BI连接ODBC数据源,这个时候是支持编写SQL查询的。
总结:如果是从数据库加载的数据,建议优先使用SQL进行类似的计算,然后使用Power Query加载这段SQL。
比如,你需要加载100张表到模型中,使用了一些数据源。在后续的维护中,数据库的数据进行了迁移,则需要对不同的数据来源进行调整。如果没有事先把路径作为参数,那么再修改来源的时候,会增加必须要的量。
当然,参数化的使用不仅仅局限于此,使用的场景很广泛,在设计时,需要提前考虑。
总结:参数化是设计的初衷,为了解耦,耦合太深会增加很多不必要的工作量。
Power BI是有一套自己的运行规则,初学者在使用Power BI时,会想当然的按照自己的理解来使用Power BI,由于方法不对,会产生一种Power BI也不过如此的错觉,真正的原因可能是,打开的方式不对。
简单来说,Power BI使用维度建模,尽量减少在事实表上的维度,将维度单独成表,通过关系,将维度表与事实表进行关联,使数据塌缩到最小维度。一方面可以提高运算速度,另一方面可以减少文件内存占用。
最简单的实践操作就是,事实表去维度化,将维度单独成表,使用表关系与事实表关联。
总结:掌握一些维度建模的知识,了解什么是维度建模,才能更好的使用Power BI。Power BI和那些号称是BI,结果背后还是在拼大宽表的BI工具,是完全不同的。
Power BI虽然强大,但是架不住一股脑的塞数据。因此,在实际的建模或分析过程中,除了优化加载的表列,还需要对分析所用的数据粒度进行整合。
比如分析只看到月,那么就没必要加载到每天的数据。数据分析只看到天,就没必要添加到小时或分分钟维度的数据。
总结:选用合适的数据粒度,让工作事半功倍。
请注意,此处说的是减少使用,不是不能使用。这主要基于两个方面的考虑。
一方面,对于新手,无法编写复杂的DAX,那么可以使用新建列来减少难度,但同时需要明白,添加列这个动作,自己到底在做什么,而不是无脑的使用新建列进行辅助计算。
另一方面则是,计算速度和内存之间的平衡。比如增加一列之后,能极大的提高某个度量值的计算速度,那么为了不影响可视化的展示,是可以牺牲掉内存来保计算效率的。
编写的度量值,默认会放到你选择的那个表,或者默认放在排序在一个的表中。这样的度量值不利于管理,推荐的方法是,新建一个表,然后用于存放度量值。同时仍可以在表中,增加文件夹来管理这些度量值。
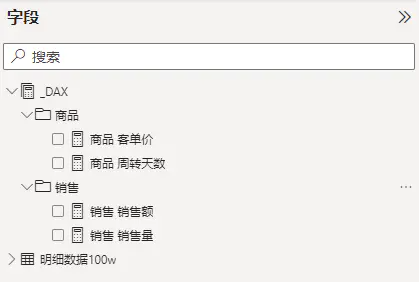
度量值管理关于这部分,网上已经有很多人写了相关的文章,我不做细节的展开,如需要可以参考:
简单三个步骤,轻松管理你的Power BI度量值
https://zhuanlan.zhihu.com/p/99394463
表命名
表的命名上,每个人都可以采用自己的一套规则。前提是能清晰的区分出来不同功能的表,比如从命名规则上,是否可以区分出事实表、维度表、参数表、辅助计算的视图表等等。举例:
事实表:F Model 销售明细
维度表:D Model 商品主数据
参数表:C Model 天数
视图表:D View 辅助作图
度量值命名:度量值的命名规则推荐使用定语后置。举例:
- 销售 销售额
- 销售 销售额 直营
- 销售 销售额 直营 A品
- 销售 销售额 直营 A品 去年
- 销售 销售额 直营 A品 同比 %
在基础度量值名称的基础上,通过不断在后面添加描述。这样命名有两个好处:
- 相似逻辑的度量值排序上紧挨在一起,方便查找和对比,而且看起来非常清晰;
- 由于规则清晰,在编写DAX公式时,可以直接将度量值写出来,节省了查找和记忆不同度量值名称的时间。
模型分层主要在复杂模型中做为一种解决方案。
该功能的实现,依赖于将同一个度量值显示在不同的文件夹中进行管理。
举例:
模型层:将直接取之于事实表的度量值,放到模型层。当源数据有逻辑变动时,仅需要修改模型层的度量值即可。
视图层:视图层的度量值,全部取值于模型层,当模型层的度量值变更时,视图层度量值不用单独维护。包括一些为特殊可视化所编写的度量值,也放在该文件夹下。比如也可以每页可视化报告做一个子文件夹,用于管理可视化页面上的度量值。
项目层:项目层是一个更大的概念。比如在一个模型中,有不同的分析项目,而每个分析项目又有很多可视化页面。某个特定的项目,从不同的场景中取了一些度量值。由于使用的度量值散落于各处,当我们查看某个项目相关的指标时,可以将该项目使用的度量值,都显示在被命名为该项目的文件夹下。
关系视图中,选中度量值,在显示文件夹中,以逗号间隔,就可以将同一个度量值,显示在多个文件夹下面。
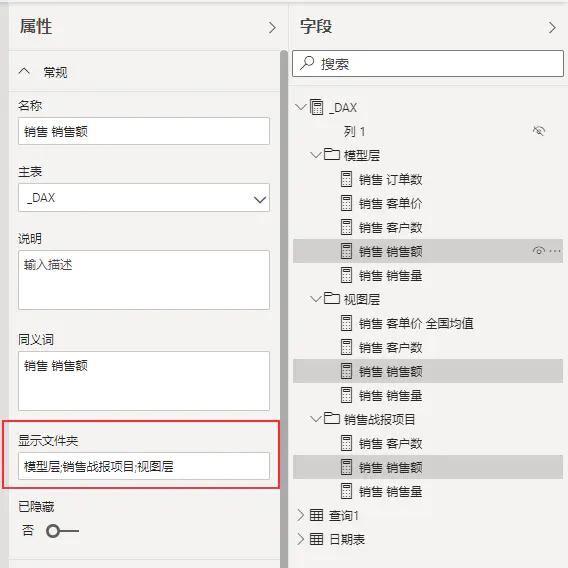
请永远使用一对多关系,除非你知道你在做什么。
为什么不推荐使用多对多,或者多对一,是计算结果不正确吗?其实不是这样的,原因是按照一对多的关系进行思考和公式的编写,可以让模型关系变得简单和易于理解。而多对多和多对一的关系则会让模型内部的交互变得复杂,而造成模型关系混乱。
请注意,并不是禁止使用,既然设计了这样的功能,就有其使用的价值。前提就是当你使用多对多关系或者使用多对一关系时,你需要明白你自己真正在做的是什么,而不是随随便便拉一根线那么简单。
比如在做权限控制的一些场景中,则需要开启多对多的双向安全筛选。这种情况下就必须使用多对多关系才能完成。
总结:在你真正理解Power BI模型关系之前,建议请遵守该条规定,可以让你的模型更简单。
反结构化的设计初衷在于为了满足某种诉求,用于牺牲设计上的规范,同时这个诉求又非常的合理。
比如你有一份商品主数据,同时有一份手工指定的特殊商品清单。按照维度建模的规范,应该将该特殊指定的表,作为商品主数据的维度表,组成雪花模型。
规范设计下,数据大小的占用。
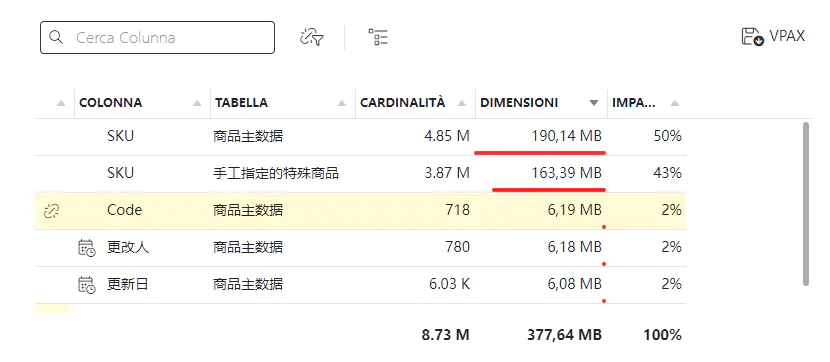
在设计上很规范,没有问题,然而我们发现一个新的现象。
如果把这份特殊的商品清单,在商品主数据上,新增一列,将符合的SKU标记为1。
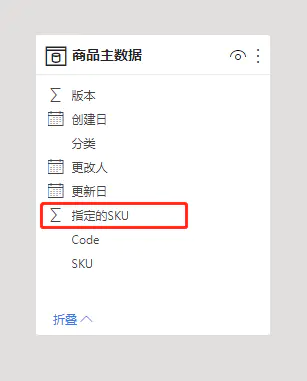
再看下反结构化设计下,数据大小的占用。
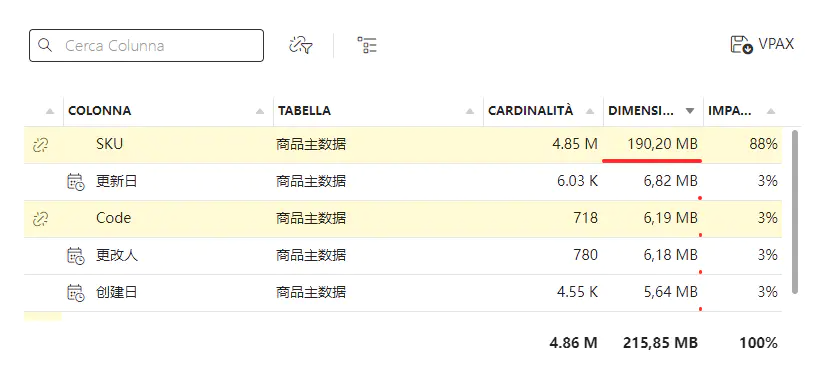
两个PBIX文件大小的对比。
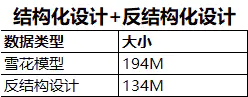
从文件实际的大小来看,采用反结构设计,可以节省30%的空间占用。30%的空间优化对于一个模型来说非常的有诱惑力。
总结:这只是一个缩影,可以推广到很多具体的使用场景,甚至可以反设计到事实表上,具体可以灵活掌握。在做这件事之前,一定要清楚你在做什么,而不是无脑加列。前提还是在模型规范化设计的基础上,在局部使用,而不是完全进行反结构化设计,一定要认清反结构化设计的初衷是什么。
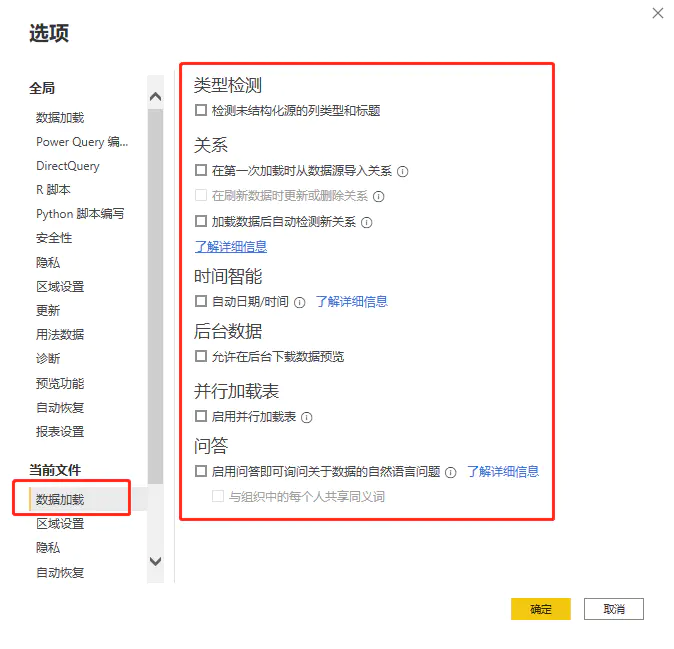
- 类型检测 在Power Query中,会自动针对新加载的表检测数据类型,并产生一个新的操作步骤,貌似很智能,其实潜在隐患很大。
- 对于新手,这很容易造成自动检测的数据类型与预想的数据类型不一致,导致后续的计算出现问题,而又不能很好的发现问题所在。
- 因此,在实际操作中,关闭该选项,表中所有字段的字段类型均由自己指定。
- 关系 关系的自动检测,遵循自己的一套规则。比如两张表有相同的字段名称,同时符合一对多关系,那么会自动创建该该关系。自动的关系检测也建议关闭,所有的表关系一定是由自己指定,而不使用系统自动检测的任何关系。因为默认检测到的表关系,不一定是自己需要的关系,从而增加修改工作量。
- 时间智能 该功能会自动将日期创建为日期层次结构。好处是直接可以拖出来日期层次进行分析,然而实际的分析中,很少这样用到,还用对用户造成困扰。因此在实际建模过程中,该功能建议关闭。
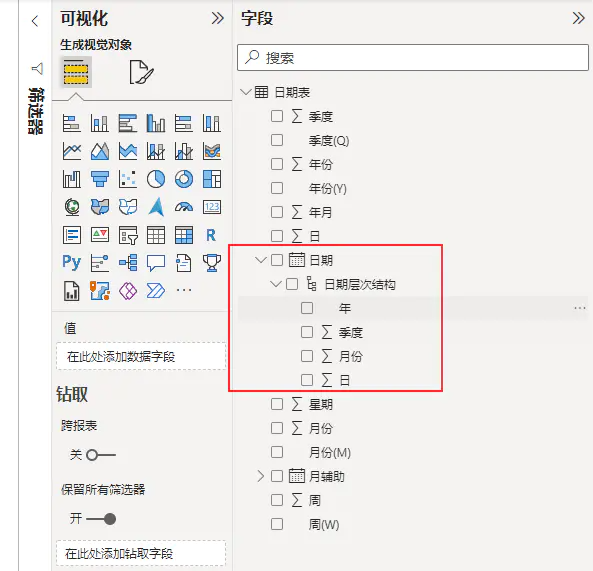
- 后台数据 建议关闭,该功能会在打开Power Query时,自动预览所有查询的前1000行数据,如果查询的数据比较大,或计算量比较大,则会消耗本地资源。然而这还不是最坏的情况,最坏的情况是,这会增加数据库的访问,增加服务器资源的消耗。
比如在Power Query中加载了一个1亿行的表,如果该功能不关闭,那么在打开Power Query时,该查询会从数据库获取这1亿数据,并展示前1000行数据的预览。在展示前1000行之前,数据库需要将1亿数据所在的表,全部加载到内存中,然后才从内存读取前1000行,对服务器造成不必要的压力,甚至会造成服务器的瘫痪。
关闭该功能后,如果需要查看某个查询的最新结果,可以在选择对应的表查询后,点击刷新预览按钮,则只刷新当前表的数据。

- 并行加载表 在数据量较大且查询较多的情况下,会增加服务器的压力,建议关闭。在数量不大且表不多的情况下,是否勾选可酌情调整。
- 问答 该功能一般情况下用不到,用到的时候再打开即可。
DAX公式主要是由FE(公式)引擎和SE(存储)引擎共同作用的结果。
执行 DAX 查询涉及两个引擎:
- 公式引擎处理请求,生成并执行查询计划。
- 存储引擎从表格模型中检索数据以响应公式引擎提出的请求。
- 存储引擎有两种实现:
- VertiPaq在内存中托管数据的副本,该副本会定期从数据源刷新。
- DirectQuery将查询直接转发到每个请求的原始数据源。
- 公式引擎是查询引擎的更高级别的执行单元。
- 它可以处理 DAX 请求的所有操作。
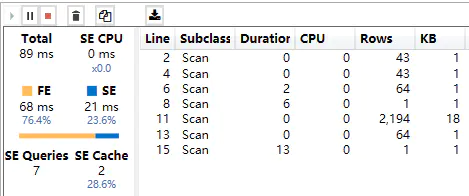
在DAX公式的优化方向上,则希望优先使用FE引擎计算,尽可能减少SE引擎的计算或增加SE缓存命中的数量。
公式的计算效果有三种状态:
- 最好:只有FE产生计算;
- 一般:FE和SE共同计算,第二次执行能全部命中或部分命中SE缓存;
- 较差:FE和SE共同计算,第二次执行仍无法命中SE缓存;
请注意:DAX的公式优化,在很多时候是有极限的,优化到一定地步就无法再优化。
在某些场景下,公式的算法进行优化后,可能会有几倍甚至几百倍上千倍的性能差异,在解决特定计算场景时,优化DAX算法或者公式的编写技巧,是非常有必要的。
这部分佐罗老师写的更详细,大家直接参考即可:
PowerBI DAX中有哪些性能优化方法?
https://www.zhihu.com/question/479286572/answer/2056793897
比如使用佐罗老师的,视图层算法。在很多场景中,是可以提高计算速度的。
关于视图层算法,请参考:
20200803 PowerBI DAX 性能优化 高级视图算法 性能提升成千上万倍
https://www.jianshu.com/p/5080bb795be9
总结:DAX公式的性能优化,需要积累一定的知识储备才能达到更好的效果。也可以通过探索DAX函数的计算原理,搭配出最佳函数组合,用以达到最佳计算性能。
减少报表页面可视化图表的数量,可以减少图表渲染的时间,从而增加页面加载的速度。
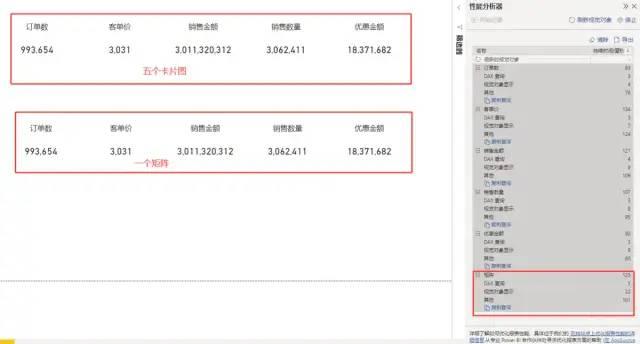
比如我们要做5个不同指标的卡片图,那么我们有两个选择。一个是使用5张卡片图,另一个是使用矩阵。
虽然都是计算5个指标,但其实际在页面加载的速度则有明显的区别。
比如,下面的图片中。效果看起来是完全一样的,不过上面是5个卡片图,下面是一个矩阵。实际页面加载中,下面的矩阵只渲染一张图表,因此速度快了5倍左右。
除此之外,建议优先使用默认的视觉对象。相较于应用市场中的视觉对象,默认的视觉对象加载更快。
总结:报表可视化页面,视觉对象的数量要适当,太多容易造成加载速度变慢,太少又会造成内容不够丰满。
增量刷新适合以下场景:
- 不经常改动模型;
- 增量数据较大,刷新时间过长;
- 可以得到IT在数据库方面的支持;
- 有Pro账号或企业级账号;
增量刷新,则可以看我的另一篇文章:
Power BI增量刷新如何配置(颠覆认知)
https://www.jianshu.com/p/d388f7891912
总结:增量刷新在规范的项目中,是不错的选择。但如果你只是在本地分析,则无法使用该功能。
减少列不重复值,是缩小Power BI文件大小的方法。
Power BI表格模型的数据存储于 VertiPaq,这是一个位于内存中的列式数据库,与行式数据库不同,这是一种以列形式存储数据的结构。
这部分请参考高飞老师的讲解:
理解基数 Cardinality
https://www.powerbigeek.com/understanding-columns-cardinality/
这是一种存储机制,可以缩小表格存储所需的空间。
总结:举例来说,对于日期时间的处理,最佳实践就是:日期和时间分开两列,若时间不参与计算,则不加载。如果将日期和时间放在一列,则会增加列基数,文件会变的更大。
以上讲过了Power BI在软件上的优化。软件的优化是有一定局限性的,若硬件不与之匹配,则软件的优化效果不会太明显。因此,在Power BI性能优化最佳实践中,硬件优化是最直接,最简的方式。那么,如何通过硬件的提升,来提高Power BI的运算速度呢,该提哪部分配置性价比最高呢?
1、CPU
CPU是影响Power BI计算速度的第一因素,且是CPU单核性能。而市面上这样的CPU往往还都比较便宜,5000元左右的预算,就可以买到一个相当不错的机器。
CPU性能,参考网站:
https://www.cpubenchmark.net/CPU_mega_page.html
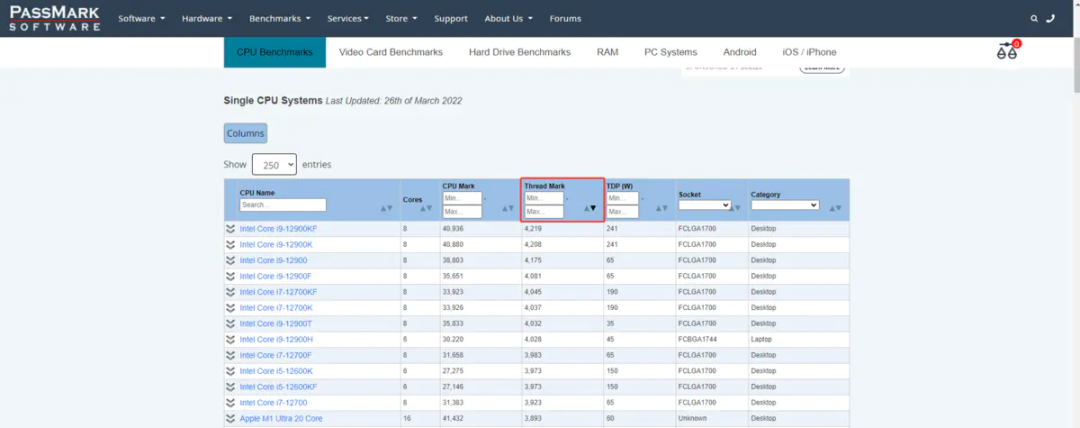
按照Thread Mark倒序,从大到小,即可看出CPU一列中,哪个CPU排名最靠前,那么这个CPU在计算Power BI的时候就越快。
截止发文,计算Power BI最快的CPU是I9-12900KF,不过这样的CPU价格都比较贵,可以退而求其次,找到一个性价比比较高的CPU,比如I7-12700H。
关于如何测试你电脑CPU的性能在什么级别,可以参考佐罗的文章:
PowerBI轻松测试电脑性能,帮您选好电脑
https://zhuanlan.zhihu.com/p/399416479
CPU的使用建议是,测试的时长不超过10秒,原则上越快越好。目前我遇到过最快的,大概在4秒,我自用的电脑在6秒-7秒,你也测测你电脑CPU的性能吧!
总结:CPU的升级,是最直接最简单提升Power BI计算速度的方法。这部分的提升,是DAX性能优化所无法弥补的。
2、内存
在内存方面,很多人都会认为,内存越大,计算越快。在Power BI的计算中,实际并不是这样,真正影响Power BI计算速度的是内存频率。一个频率是4800HZ的8G内存,是一定比一个频率是2666HZ的32G内存计算更快的。
内存频率变化的直观感受,反映到Power BI的操作中就是,你写完一个度量值并回车,很快就执行完成。反之就是你还需要等待3-5秒才计算完成,尤其是在一些复杂的计算中,这个时间差异尤为明显。
该经验主要来源于,我使用同一个模型在不同的电脑上进行测试的结果。
- 使用了一台旧电脑,新建度量值反应11-12秒;
- 使用I5-1135G7 CPU,搭配2666HZ内存,新建度量值反应8-9秒;
- 使用I5-1135G7 CPU,搭配3200HZ内存,新建度量值反应6-7秒;
这块的数据不算太严谨,之所以写出来,仅希望做个参考。- 因所使用的的模型不同,其他人无法复现,有待更多人的更多测试数据。
目前从理论上来说,肯定是内存频率越高,计算速度越快。
截至发文,市面上主流的内存频率是3200HZ,并且已经出现了搭载诸如4800HZ、5600HZ内存频率的电脑。作为个人推荐的话,建议不低于3200HZ,如果有条件,那当然是越快越好啦!
总结: CPU(单核性能) > 内存频率 > 内存大小
3、其他
其他部分包括:硬盘、网卡、网速等。在Power BI的部署和生产环境中,依然也会产生不同的影响。比如显卡会影响页面渲染的速度,网速会影响可视化加载的速度等等。
4、企业级硬件部署
本地部署
企业级的本地部署,Power BI一般都会放到专用的服务器上。基于以上总结过的硬件配置经验,实际在计算过程中,企业级的服务器,在表现上,可能不如5000元的笔记本。服务器的配置偏重一般都在多核并行计算上,但单核性能的表现上却很一般。所以,企业级的本地部署,需要考虑下服务器的硬件搭配,尤其是CPU类型,同时平衡单核性能和并发。
云端部署
同样的道理,目前经过测试后的数据显示。即便使用Power BI Premium,其计算速度依然不如5000元的笔记本更快。
如果只是个人使用Power BI,你花5000元买个笔记本,完全不用自卑,因为已经比企业级的部署更快了。
云端加更多的资源,解决的还是高并发,对于单个用户而言,速度上不会有明显的变化。
关于云端计算速度和本地PC电脑计算速度的对比,请参考:
https://jishuin.proginn.com/p/763bfbd32a8c
新的版本,往往意味着更多的功能和更优秀的性能。定期更新到较新的版本,也有助于对Power BI的优化。
全文总结:
最佳实践就是平衡的艺术。
Power BI性能优化最佳实践的核心就是平衡,了解自己所需的和可以舍弃的,从而找到最佳平衡点。最佳实践不是结果,而是状态。
由于文中涉及大量的专业知识,受限于作者的水平,可能存在有误的地方。若发现错误之处,不吝赐教。


