

首发Yolov8优化:Adam该换了!斯坦福最新Sophia优化器,比Adam快2倍
发布时间:2024-07-08 点击量:68
斯坦福2023.5月发表的最新研究成果,他们提出了「一种叫Sophia的优化器,相比Adam,它在LLM上能够快2倍,可以大幅降低训练成本」。

论文:https://arxiv.org/pdf/2305.14342.pdf
本文介绍了一种新的模型预训练优化器:Sophia(Second-order Clipped Stochastic Optimization),这是一种轻量级二阶优化器,它使用Hessian对角线的廉价随机估计作为预调节器,并通过限幅机制来控制最坏情况下的更新大小
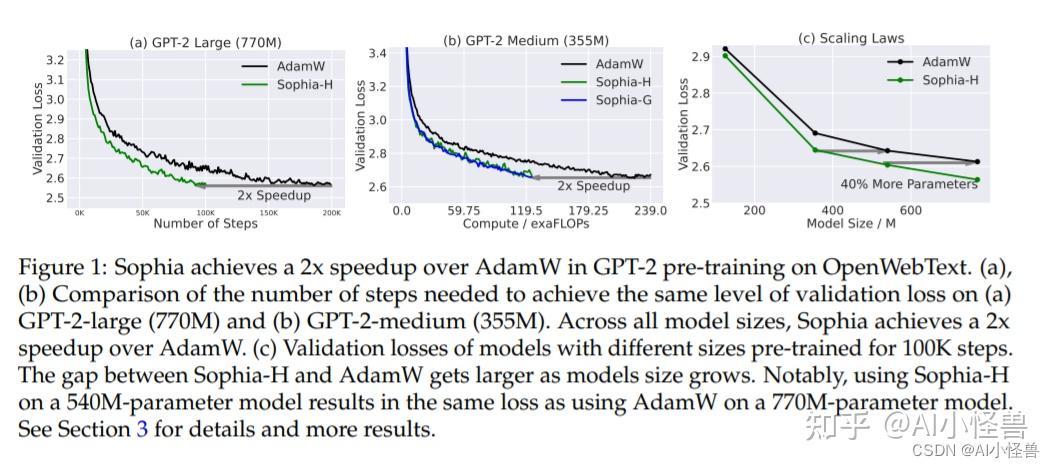
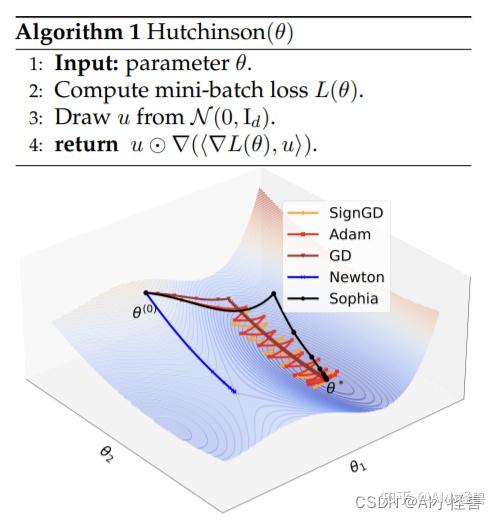
?该研究设计了一种新的优化器 Sophia,它比 Adam 更适应异构曲率,比 Newton 方法更能抵抗非凸性和 Hessian 的快速变化,并且还使用了成本较低的 pre-conditioner。

加入以下代码
elif name=='SophiaG':
optimizer=torch.optim.SophiaG(g[2], lr=lr, betas=(momentum, 0.999), rho=0.04, weight_decay=0.0)
?
? ?sophia.py代码如下:
import torch
from torch.optim.optimizer import Optimizer
import math
from torch import Tensor
from typing import List, Optional
class Sophia(Optimizer):
def __init__(self, model, input_data, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, k=10,
estimator="Hutchinson", rho=1):
self.model=model
self.input_data=input_data
defaults=dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, k=k, estimator=estimator, rho=rho)
super(Sophia, self).__init__(params, defaults)
def step(self, closure=None):
loss=None
if closure is not None:
loss=closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad=p.grad.data
if grad.is_sparse:
raise RuntimeError("Sophia does not support sparse gradients")
state=self.state[p]
# state init
if len(state)==0:
state['step']=0
state['m']=torch.zeros_like(p.data)
state['h']=torch.zeros_like(p.data)
m, h=state['m'], state['h']
beta1, beta2=group['betas']
state['step']+=1
if group['weight_decay']!=0:
grad=grad.add(group["weight_decay"], p.data)
# update biased first moment estimate
m.mul_(beta1).add_(1 - beta1, grad)
# update hessian estimate
if state['step']% group['k']==1:
if group['estimator']=="Hutchinson":
hessian_estimate=self.hutchinson(p, grad)
elif group['estimator']=="Gauss-Newton-Bartlett":
hessian_estimate=self.gauss_newton_bartlett(p, grad)
else:
raise ValueError("Invalid estimator choice")
h.mul_(beta2).add_(1 - beta2, hessian_estimate)
# update params
p.data.add_(-group['lr']* group['weight_decay'], p.data)
p.data.addcdiv_(-group['lr'], m, h.add(group['eps']).clamp(max=group['rho']))
return loss
def hutchinson(self, p, grad):
u=torch.randn_like(grad)
grad_dot_u=torch.sum(grad * u)
hessian_vector_product=torch.autograd.grad(grad_dot_u, p, retain_graph=True)[0]
return u * hessian_vector_product
def gauss_newton_bartlett(self, p, grad):
B=len(self.input_data)
logits=[self.model(xb) for xb in self.input_data]
y_hats=[torch.softmax(logit, dim=0) for logit in logits]
g_hat=\\
torch.autograd.grad(sum([self.loss_function(logit, y_hat) for logit, y_hat in zip(logits, y_hats)]) / B, p,
retain_graph=True)[0]
return B * g_hat * g_hat
class SophiaG(Optimizer):
def __init__(self, params, lr=1e-4, betas=(0.965, 0.99), rho=0.04,
weight_decay=1e-1, *, maximize: bool=False,
capturable: bool=False):
if not 0.0 <=lr:
raise ValueError("Invalid learning rate:{}".format(lr))
if not 0.0 <=betas[0]< 1.0:
raise ValueError("Invalid beta parameter at index 0:{}".format(betas[0]))
if not 0.0 <=betas[1]< 1.0:
raise ValueError("Invalid beta parameter at index 1:{}".format(betas[1]))
if not 0.0 <=rho:
raise ValueError("Invalid rho parameter at index 1:{}".format(rho))
if not 0.0 <=weight_decay:
raise ValueError("Invalid weight_decay value:{}".format(weight_decay))
defaults=dict(lr=lr, betas=betas, rho=rho,
weight_decay=weight_decay,
maximize=maximize, capturable=capturable)
super(SophiaG, self).__init__(params, defaults)
def __setstate__(self, state):
super().__setstate__(state)
for group in self.param_groups:
group.setdefault('maximize', False)
group.setdefault('capturable', False)
state_values=list(self.state.values())
step_is_tensor=(len(state_values) !=0) and torch.is_tensor(state_values[0]['step'])
if not step_is_tensor:
for s in state_values:
s['step']=torch.tensor(float(s['step']))
@torch.no_grad()
def update_hessian(self):
for group in self.param_groups:
beta1, beta2=group['betas']
for p in group['params']:
if p.grad is None:
continue
state=self.state[p]
if len(state)==0:
state['step']=torch.zeros((1,), dtype=torch.float, device=p.device) \\
if self.defaults['capturable']else torch.tensor(0.)
state['exp_avg']=torch.zeros_like(p, memory_format=torch.preserve_format)
state['hessian']=torch.zeros_like(p, memory_format=torch.preserve_format)
if 'hessian' not in state.keys():
state['hessian']=torch.zeros_like(p, memory_format=torch.preserve_format)
state['hessian'].mul_(beta2).addcmul_(p.grad, p.grad, value=1 - beta2)
@torch.no_grad()
def step(self, closure=None, bs=5120):
loss=None
if closure is not None:
with torch.enable_grad():
loss=closure()
for group in self.param_groups:
params_with_grad=[]
grads=[]
exp_avgs=[]
state_steps=[]
hessian=[]
beta1, beta2=group['betas']
for p in group['params']:
if p.grad is None:
continue
params_with_grad.append(p)
if p.grad.is_sparse:
raise RuntimeError('Hero does not support sparse gradients')
grads.append(p.grad)
state=self.state[p]
# State initialization
if len(state)==0:
state['step']=torch.zeros((1,), dtype=torch.float, device=p.device) \\
if self.defaults['capturable']else torch.tensor(0.)
state['exp_avg']=torch.zeros_like(p, memory_format=torch.preserve_format)
state['hessian']=torch.zeros_like(p, memory_format=torch.preserve_format)
if 'hessian' not in state.keys():
state['hessian']=torch.zeros_like(p, memory_format=torch.preserve_format)
exp_avgs.append(state['exp_avg'])
state_steps.append(state['step'])
hessian.append(state['hessian'])
if self.defaults['capturable']:
bs=torch.ones((1,), dtype=torch.float, device=p.device) * bs
sophiag(params_with_grad,
grads,
exp_avgs,
hessian,
state_steps,
bs=bs,
beta1=beta1,
beta2=beta2,
rho=group['rho'],
lr=group['lr'],
weight_decay=group['weight_decay'],
maximize=group['maximize'],
capturable=group['capturable'])
return loss
def sophiag(params: List[Tensor],
grads: List[Tensor],
exp_avgs: List[Tensor],
hessian: List[Tensor],
state_steps: List[Tensor],
capturable: bool=False,
*,
bs: int,
beta1: float,
beta2: float,
rho: float,
lr: float,
weight_decay: float,
maximize: bool):
if not all(isinstance(t, torch.Tensor) for t in state_steps):
raise RuntimeError("API has changed, `state_steps` argument must contain a list of singleton tensors")
func=_single_tensor_sophiag
#
func(params,
grads,
exp_avgs,
hessian,
state_steps,
bs=bs,
beta1=beta1,
beta2=beta2,
rho=rho,
lr=lr,
weight_decay=weight_decay,
maximize=maximize,
capturable=capturable)
def _single_tensor_sophiag(params: List[Tensor],
grads: List[Tensor],
exp_avgs: List[Tensor],
hessian: List[Tensor],
state_steps: List[Tensor],
*,
bs: int,
beta1: float,
beta2: float,
rho: float,
lr: float,
weight_decay: float,
maximize: bool,
capturable: bool):
for i, param in enumerate(params):
grad=grads[i]if not maximize else -grads[i]
exp_avg=exp_avgs[i]
hess=hessian[i]
step_t=state_steps[i]
if capturable:
assert param.is_cuda and step_t.is_cuda and bs.is_cuda
if torch.is_complex(param):
grad=torch.view_as_real(grad)
exp_avg=torch.view_as_real(exp_avg)
hess=torch.view_as_real(hess)
param=torch.view_as_real(param)
# update step
step_t +=1
# Perform stepweight decay
param.mul_(1 - lr * weight_decay)
# Decay the first and second moment running average coefficient
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
if capturable:
step=step_t
step_size=lr
step_size_neg=step_size.neg()
ratio=(exp_avg.abs() / (rho * bs * hess + 1e-15)).clamp(None, 1)
param.addcmul_(exp_avg.sign(), ratio, value=step_size_neg)
else:
step=step_t.item()
step_size_neg=- lr
ratio=(exp_avg.abs() / (rho * bs * hess + 1e-15)).clamp(None, 1)
param.addcmul_(exp_avg.sign(), ratio, value=step_size_neg)代码详见和具体步骤如下:


